


Кто-нибудь еще участвовал в прошедшем ICFPC?
Предлагаю здесь пообсуждать решения, впечатления и набранное количество очков.
Вкратце опишу наш подход.
Simple problems
Для задач без оператора fold мы придумали решение, которое работало лучше чем полный перебор:
- Сначала делаем прекальк.
- Выбираем случайным образом
X— вектор длины 5-10 из случайных 64 битных чисел. - Динамикой вычисляем какие могут быть вектора значений функций сложности не больше
N, на этом набореX. ЧислоNопределялось таким образом, чтобы общее количество вариантов не превосходило10^6. - Теперь делаем запрос
evalна сервер c этим векторомX. - По полученному
Yначинаем раскручивать динамику назад и восстанавливать какие функции могут принимать такие значения. - Каждую подходящую функцию пытаемся отправить на сервер в качестве ответа.
- Если она не подходит, то сервер нам выдает
(x, y)-- ограничение на функцию видаf(x) = y. Продолжаем раскручивать динамику, предварительно отфильтровывая функции не удовлетворяющие этому ограничению.
Наборов значений существенно меньше, чем всего функций, поэтому это работает лучше чем полный перебор.
Problems with fold
В задачках, содержащих fold уже надо было перебирать функции зависящие не только от переменной x, но и от переменных y, z. Поэтому этот же метод применить не удалось. Здесь мы использовали обычный итеративный brute force:
- Аналогичным образом, генерим случайный вектор
Xи с сервера спрашиваем векторYзначений искомой функции. Эта пара(X, Y)задает нам ограничение на искомую функцию. - Начинаем перебирать все функции по порядку от меньших сложностей к большим.
- Если функция подходит под ограничение то либо она и есть искомая и мы решили задачу, либо наше ограничение
(X, Y)увеличивается и мы продолжаем дальше наш перебор.
Большую часть контеста мы пытались придумать решение более умное чем полный перебор, но все нашли эксперименты не взлетали. Примерно за 16 часов до окончания соревнования мы поняли, что даже если и придумаем что-то круто, то не успеем это закодить/отладить и начали просто подряд решать все задачки описанными выше алгоритмами. Успели за 15 минут до конца контеста :) (правда для этого пришлось в последний час поставить таймлимит в 1 минуту на задачу вместо 5).
Как было замечено на небольших сложностях (да и сами организаторы говорили про это на сайте), что часто правильным ответом может быть функция существенно меньшей сложности, чем заявлено в условии. Поэтому таким методом можно получить очков за достаточно большое количество задач.
Общее впечталение
К недостаткам этого контеста стоит отнести следующее:
- Задачка в основном сводилась к оптимизации перебора (что не очень весело и дает преимущество тем у кого есть много CPU power). Хотя, возможно, топовые команды и придумали что-то интересное. Мы пытались гуглить state of the art подходы к этому делу -- нашли какую-то микрософтовскую статью про применение SMT. Но статья ограничивалась описанием в стиле "мы тут придумали клевый алгоритм, который имеет меньше чем экспоненциальную сложность, но как его закодить вы все равно не поймете".
- Организаторы почему-то сознательно не стали делать публичный scoreboard. Мне совершенно непонятна мотивация этого решения -- ведь так убивается весь соревновательный дух.
К положительным моментам стоит отнести, что в этом году сервера организаторов работали исправно, багов практически замечено не было, публичный api был удобным, ограничения на ddos были четко прописаны. Поэтому, в целом я считаю контест очень неплохим. Лучше чем прошлогодний про перебор путей в графе, но хуже чем 2010 и 2011 года.
PS. Мы набрали 1182 очка. По последним сообщениям с оффсайта это соответствует примерно 40му месту:
We have clear separations between the scores of the top 3 teams.
#11 is at around 1400.
#25 is at around 1250.
#50 is at around 1100.
#75 is at 904
#100 is at 701
#125 is at 568
#150 is at 428
#175 is at 291
#200 is at 206
#225 is at 116
#250 is at 38
#275 is at 0
Кому интересно, наш код доступен на гитхабе: https://github.com/pankdm/icfpc-2013 (однако, к концу третих суток соревнования он окончательно превратился в тыкву).
PPS. Кстати, на http://labs.skbkontur.ru/icfpc2013/ есть клевый визуализатор набранных очков: 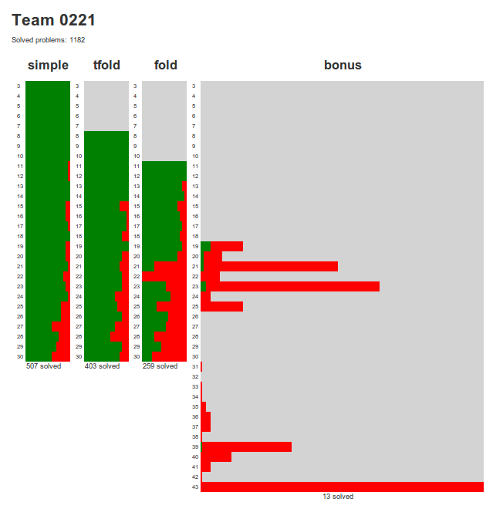
PPPS. Отчеты других команд:
- nbu (1458)
- THIRTEEN (1456)
- (unmatched (1301)







Почти там же (http://labs.skbkontur.ru/icfpc2013/stats) есть неофициальный scoreboard из тех, кто поделился своей информацией на этой странице.
Мы тоже участвовали (команда Gassa_and_naagi), набрали 128 в lightning и 997 в основном зачёте.
Подход в целом тоже характеризуется как полный перебор с отсечениями. Строим выражения от меньших к большим, начиная с
0,1иx(ещёyиzдляfold). Отсечения случаются не заранее динамикой, а прямо при построении выражения. Для начала руками. Например:shr*упорядочиваются (то есть строимshr1 shr4 x, но пропускаемshr4 shr1 x),0не имеет смысла делать что-либо унарное или бинарное, кромеnot,x and 1, но пропускаем1 and x),1 plus (x plus f(x)), но пропускаем остальные пять перестановок1,xиf(x)).Ну и немного автоматики, которая требует времени и памяти, но разбирает более сложные случаи совпадения:
if0иfold) функций отxзапускаем их на заранее сгенерированном небольшом векторе входов (все нули, все единицы и два случайных числа) и оставляем только те, которые выдали различные результаты.В
simpleиfoldдаже задачи большого размера очень часто имели короткие решения, которые этот перебор успевал найти. А задачи сtfold, начиная с размера 17, почему-то не пошли.В первой пачке бонусных задач в тренировке можно было заметить структуру:
ifzero (f(x) and 1) then (g(x)) else (h(x)), гдеf,gиhне очень большого размера. Соответственно, решаем в три этапа:Находим
g(илиh), которая работает хотя бы примерно на половине случайных вводов — по принципу Дирихле такая половина есть.Находим к ней пару, которая решает правильно все не решаемые ею вводы.
Находим условие, которое именно так распределяет вводы.
Второй пачкой бонусов не занимались — у нас решение для первой заработало за 15 минут до конца.
Выложил наш код (на D) на Github.
UPD: картинка про сданные задачи.
Круто! Спасибо за рассказ.
Я тоже использовал кое-какие отсечения в переборе:
v. Для каждогоvбудем брать только самое простое выражение.(if0 const ...)тоже можно не рассматриватьИ все.
Другие типы я не прикручивал, так как в какой-то момент появилась идея хешировать функции получаемые в процессе перебора по значениям на векторе X. В этом случае все упрощения эквивалентных функций не нужны, так как они будут автоматически отсекаться хэшированием.
Для функций без фолда она бы работала (так как нам от сервера приходили бы все новые переменные x, улучшающие хэш и избавляющие от коллизий). Но наше решение динамикой казалось нам более перспективным.
Эту же идею (считаем хэш уже по векторам из трех переменных) я реализовал на фолде. Но довольно быстро обломился, так как не нашел способа улучшать хэш на основе приходящий от сервера ответов. То есть из-за коллизий мы откидываем куски хороших функций и уже никогда их не получим.
Странно, что у вас не пошли задачки c
tfold. Там тоже было очень много простых задач. Может какая бага в переборе?А мы, к сожалению, проглядели структуру бонусных задач и решали их нашим обычным методом (что понятно дело работало плохо), поэтому потеряли прилично очков на этом.
О, забыл спросить. А у вас случайно нет данных насколько улучшается перебор при использованных вами отсечениях?
По поводу своих у меня есть такие данные: Если брать задачки из
myproblemsбезfold-а размера до 10 (чтобы быстро можно было оценить), пункт 3. дает в среднем улучшение примерно в2.44раза, пункт 2. — в1.57. Пункт 1. был написан сразу, поэтому его я не оценивал.У нас до последнего была надежда, что мы найдем решение в котором неасимптотические отсечения в переборе не будут играть роли. Но в итоге все равно пришлось решать все перебором.
Ну вот сейчас попробовал на случайных simple 30 задачах посмотреть количество выражений размера 7. Безо всех отсечений получается порядка 10 000, со всеми отсечениями порядка 200 000 (**upd:** наоборот, конечно).
Во время контеста критерий был «стал ли решаться следующий размер в тренировке», во сколько раз стало лучше — не оценивали.
Вот пример лога для train simple 30, тут есть некоторая статистика отсечений по мере построения всех выражений некоторого размера:
[сколько всего построено]packразмер, lengthсколько этого размера, const +различных констант-было дубликатов, overx +различных выражений от x-было дубликатовВидно, что и const, и overx оптимизации (уже после применения всех ручных) сделаны не зря.
Сгенерил ради сравнения на этом же примере своим генератором (которым я решал задачки с фолдами):
Да, у вас поменьше раза в 3 вариантов получается.
Кстати, какие впечатления от языка D?
Я хотел в этом году на Scala писать, но желающих не набралось, поэтому традиционно писали на питоне (там по крайней мере все грабли известны). Он, конечно, не очень быстрый, зато позволяет быстро прототипировать и библиотечки удобные. Я уже представляю себе всю радость работы с http из С++, вместо строчек.
Впечатления от языка D такие.
Сам язык похож, когда нужно быстродействие, на Си, а когда нужно быстронаписание — на Питон, например. Это очень удобно, пока всё работает.
При этом язык немного сыроват, решения некоторых вопросов на данный момент далеки от идеала (garbage collector, rvalue references).
Стандартной библиотекой можно пользоваться, но сырые куски встречаются часто.
Есть три компилятора: DMD (фактически определяющий стандарт языка) и порты под LLVM и GCC backend-ы. DMD доступен в соревнованиях на Codeforces. Он компилирует быстрее, но отстаёт по качеству оптимизации кода. Порты отстают по номеру версии языка (не пробовал их).
На реальном примере: кода icfpc2013 ~75 килобайт. Конечно, случался и copy+paste, оправданный временными рамками. Всякая мерзость вследствие выбора инструмента случалась раза три навскидку:
Библиотека curllib не работала из коробки. Пришлось собирать самому. Потом оказалось, что можно было скачать, но я вовремя не смог загуглить это место. Продолбал час-два, потому что линкер стандарта 1988 года — это отдельная песня.
От json-библиотеки есть только половина. Пришлось дописывать. Продолбал минут десять-двадцать.
Garbage collector не всегда делает то, что просят. Пришлось иметь в виду оптимизацию по памяти при написании. Потраченное время и баллы — даже минус это в итоге был или плюс — оценить трудно из-за изменившегося в результате подхода и оптимизаций.
Замечу, что не могу припомнить и добавить в этот список пункт типа «допустил сложный баг и искал его два часа», баги ловились достаточно легко. Отсутствие этой проблемы тоже в какой-то мере характеризует инструмент.
А как в таком участвуется на Питоне? Быстро получается решение, а потом долго происходит борьба за производительность? Или идеи не успевают иссякнуть, и производительность растёт за счёт улучшения асимптотики?
Я раньше писал ICFP (и короткие контесты) на C++. В D по сравнению с C++ стали проще и короче получаться обычные вещи, меньше boilerplate кода, а ещё быстрее стало отлаживать (более предсказуемо всё работает, safe by default). Зато иногда в стандартной библиотеке D внезапно обнаруживается, что нет чего-то нужного, ну или есть, но медленное или неудобное.
На питоне отлично участвуется. В предыдущие разы, когда мы писали на питоне (2010, 2011 года) производительность была не важна. Поэтому скорость разработки и удобство решали.
В 2012 году нам по задаче было понятно, что будут аналоги перебора, поэтому мы сознательно писали на С++. Но мне не понравилось писать такие вещи на С++. И не факт, что если бы мне еще раз пришлось делать такой выбор, то я бы выбрал C++.
Когда ты знаешь что писать, и понимаешь, какой алгоритм в итоге получится, то на С++ даже быстрее получается. Но когда надо много экспериментировать, то получается слишком громоздко. Да, твое решение будет оптимизированно, но не факт, что оно будет дописано. :)
Как я уже писал выше, в этот раз мы надеялись, что умные алгоритмы и хитрые оптимизации будут поднимать на несколько размеров графов вверх и уже сам язык будет неважен.
Вообще, есть мнение, что если участвовать в ICFPC не с целью изучить новый язык, то надо писать на том, что лучше всего знает команда. А такие задачи, как в этот раз (где оказался важен CPU power) это скорее исключение, чем правило.
У нас задачи естественным образом разбились на три группы: простые (т.е. совсем без fold'ов), tfold'ы и обычные fold'ы.
Простые решал я и решал примерно так. Для начала заметим, что в каждый конкретный момент времени мы решаем следующую задачу: по вектору входов и выходов найти функцию, которая на этих входах даёт эти выходы. Это принципиально отличается от исходной задачи (найти функцию, эквивалентную авторской) тем, что если мы нашли две каких-то функции, которые на этом наборе входов дают одинаковые выходы, то мы можем считать их эквивалентными и выкинуть одну из них вне зависимости от того, эквивалентны они на самом деле или нет.
Соответственно, общее решение выглядело примерно так. В одном массиве копились деревья по возрастанию размера, во втором — для каждого из этих деревьев хранился вектор его ответов на векторе входных данных. Соответственно, когда я строил очередное новое дерево, я проверял, есть ли среди ранее построенных деревьев такое, которое даёт точно такой же вектор ответов. Если да, то не добавлял его. Таким образом, у меня оставались только те деревья, которые заведомо различны, потому всевозможные ручные отсечения вроде тех, что описал Gassa, оказывались просто не нужны. Такой перебор за 5 минут успевает построить все различные деревья размера так до 14-15. Вторая ключевая идея, которая позволяла увеличить шанс решения больших задач, была следующей. Заметим, что если в дереве где-то есть if, то можно легко построить эквивалентную функцию, в которой этот if будет на самом верху. При этом размер каждого из поддеревьев будет меньше размера всего дерева. Соответственно, можно попробовать сделать следующую вешь: среди всех построенных деревьев найдём то, которое на нашем векторе входов даёт вектор выходов, максимально совпадающий с требуемым, потом попробуем найти дерево, которое даёт выходы, которые совпадают с требуемыми во всех местах, где не совпали выходы первого дерева, а потом найдём дерево, которое даёт в нужных местах нули или не нули. Я такое прогонял каждый раз, когда достраивал все деревья очередного размера. Итого это решает примерно 95% всех обычных простых задач, 100% маленьких бонусов и 30% больших бонусов (на самом деле, могло быть больше 30%, но до них руки дошли уже в последние часы, так что пришлось уменьшить отсечку по времени в несколько раз).
Вторая часть — это tfold'ы. Для них ключевое наблюдение в общем-то то же самое, что и для простых функций — вероятность, что есть эквивалентное дерево меньших размеров достаточно велика. А из-за специфики tfold'а она вдвойне велика. Соответственно, выкидываем всю логику, связанную с выкидыванием эквивалентных деревьев (тут она не работает, поскольку мы заранее не знаем, на каких входах будет вычисляться лямбда tfold'а), выкидываем логику по построению наружного if'а и оставляем по сути максимально тупой перебор, в котором единственное отсечение — это по коммутативности бинарных операций. И на удивление этого хватило, чтобы нарешать почти 90% всех задач с tfold'ами.
Про часть с обычными fold'ами я могу сказать меньше, поскольку ими занималась другая часть команды и я с ними мало взаимодействовал. Знаю лишь то, что у них был достаточно лобовой перебор, в частности, они перебирали деревья от корня, а не сливая ранее построенные. Из интеллектуального у них была какая-то такая логика: они брали вектор выходов и находили там биты, на которых всегда стоят нули либо всегда единицы. Соответственно, это им давало некоторые ограничения на то, что может быть в поддереве той или иной операции и тоже отсекало какую-то достаточную часть построенных поддеревьев. В любом случае, задачи с обычными fold'ами оказались самыми сложными и из них у нас решилось чуть больше половины.
Итоговый результат: 1499, место где-то в десятке в общем зачёте и пока ещё первое место в неофициальном scoreboard'е (который, кстати, мы написали за последние полчаса контеста, когда уже ручной работы никакой не требовалось).
А мне вот интересно, как у вас получалось на 8 (!) человек распределять деятельность? Такое ощущение, что в этом году задачка плохо параллелилась между людьми.
PS. А может вы первое место заняли и по просьбе организаторов не палитесь? :)
Задача по людям делилась действительно плохо. Я с самого начала ушёл работать сам по себе. Банально из тех соображений, что писать на шарпе под линуксом мне было несколько неудобно, а плюсы привычнее и намного предсказуемее в плане работы с памятью. Из остальных кто-то придумывал и писал какие-то отсечения к перебору, кто-то — профилировал и оптимизировал узкие места, кто-то игрался с попытками распараллелить код на несколько потоков, кто-то писал работу с сервером, кто-то — юнит-тесты на код. Ну и в целом народ часто писал код в парах. Да и из восьми человек действительно активными было вроде только шестеро.
А место своё мы и вправду не знаем. Организаторы вроде обещали его сообщить наше место после того, как мы ответим на какой-то большой опросник, который мы ещё недозаполнили.
А никто не пробовал анализировать график функции и, если он специального вида, то просто генерить такую функцию? Например, часто попадались линейные функции, причем как небольшие так и > 20 c fold-ами.
Непонятно, на что именно смотреть. Конкретно для линейных функций — если она простая (
x -> x + 1), то и так получится при переборе коротких выражений, если сложная (x -> x xor 134), то вероятность её появления в задачах, скорее всего, всё равно очень мала.Кстати, ICFP 2014, как пишут на сайте ICFP, начнётся уже в эту пятницу (25-28 июля).
Опять на D собираетесь писать? :)
Зависит от задачи. Инструмент по умолчанию — да, D.