


Собственно задача состоит в следующем, есть строка зашифрованная по RLE, т.е. представленная в виде (x1)k1(x2)k2...(xn)kn, где (xi)ki означает строку из символов ki длины xi (например строку AAABBCCC можно представить в виде (3)A(2)B(3)C). Нужно отвечать на запросы Qi, вывести Prefix(Qi). (Prefix(i) - префикс функция i-го префикса строки).
Ограничения: ki до 109, Количество блоков в RLE до 50000, запросов 105.
Предлагаю совместными усилиями "одержать" эту задачу. =)







Наверно как нибудь хэшами и бинарным поиском по значению префикс ф-ии. Правда хэш ф-я будет считаться за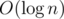 и в итоге время будет
и в итоге время будет  .
.спасибо
Потом сводить исходную задачу к этому прекалку уточненяя край.
Исхожу из того, что возможных различных символов в строке - некоторое небольшое разумное количество (пусть для этого примера - 26). Если вдруг я ошибся, и различных возможных символов много больше - прошу прощения заранее.
Пусть n - количество блоков, m - количество запросов. Будем рассматривать префикс-функцию уровня блоков.
* prefix(ki)
* elems_before(ki) - суммарное количество элементов в этом и предыдущих блоках