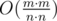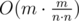Create an array used of 100 elements. i-th element for the segment
Unable to parse markup [type=CF_TEX]
.
For every student except Alexey set
Unable to parse markup [type=CF_TEX]
for each segment
Unable to parse markup [type=CF_TEX]
in the segment of that student. After that for each subsegment
Unable to parse markup [type=CF_TEX]
of Alexey's segment add 1 to result if
Unable to parse markup [type=CF_TEX]
.
First of all, calculate how many L's we can bring so that the result will not exceed N. It's
Unable to parse markup [type=CF_TEX]
.
Now, if
Unable to parse markup [type=CF_TEX]
we may increase any of
K numbers by
1. At some moment sum will be equal to
N becase sum of
K R's is greater than
N. So answer in this case is
YES.
If
Unable to parse markup [type=CF_TEX]
, we can't get
K or less numbers because their sum is less than
N. But we can't get more than
K numbers too, because their sum is more than
N. So answer is
NO.
Complexity: O(1) for every query. Overall complexity: O(t).
Let's factorize all n numbers into prime factors. Now we should solve the problem for every prime independently and multiply these answers. The number of ways to split pk into n multipliers, where p is prime, is equal to
Unable to parse markup [type=CF_TEX]
(it can be obtained using the method of stars and bars, you can read about it here, choose 'combinatorics'). So we have a solution that needs
Unable to parse markup [type=CF_TEX]
time.
First of all, let's consider
Unable to parse markup [type=CF_TEX]
is prime. Then we can prove by induction that the answer is
Unable to parse markup [type=CF_TEX]
. Base for
Unable to parse markup [type=CF_TEX]
is obvious. If this equality holds for
p, and
q is the next prime, then answer for
q is equal to answer for
p plus
Unable to parse markup [type=CF_TEX]
equal summands
Unable to parse markup [type=CF_TEX]
, that is
Unable to parse markup [type=CF_TEX]
, that's we wanted to prove.
Next using that the distance between two consecutive primes not exceeding 109 does not exceed 300, we can find the answer as a sum of the answer for the maximal prime not exceeding n and several equal summands
Unable to parse markup [type=CF_TEX]
. We see that the denominator is a divisor of
Unable to parse markup [type=CF_TEX]
, which fits in
long long.
We can write all vertices in the list in order of dfs, then the descendants of the vertex from a segment of this list. Let's count for every vertex its distance to the root
Unable to parse markup [type=CF_TEX]
.
Let's create two segment trees
Unable to parse markup [type=CF_TEX]
and
Unable to parse markup [type=CF_TEX]
. If we are given a query of the first type, in
Unable to parse markup [type=CF_TEX]
we add
Unable to parse markup [type=CF_TEX]
to the segment corresponding to the vertex
v, in
Unable to parse markup [type=CF_TEX]
we add
k to the segment corresponding to the vertex
v.
If we are given a query of the second type, we write st1.get(v) - st2.get(v) * level[v].
The complexity is O(qlogn).
You can use any other data stucture that allows to add to the segment and to find a value of an arbitrary element.
Also there exists a solution using Heavy-Light decomposition.
Let's prove a useful fact: sum of number of invertions for all permutations of size k is equal to
Unable to parse markup [type=CF_TEX]
. The prove is simple: let's change in permutation
p for every
i pi to
Unable to parse markup [type=CF_TEX]
. Then the sum of number of invertions of the first and the second permutations is
Unable to parse markup [type=CF_TEX]
, and our conversion of the permutation is a biection.
Now we suppose that we are given a permutation of numbers from 0 to n - 1.
Let's go at p from left to right. What permutations are less than p?
- Permutations having first number less than
Unable to parse markup [type=CF_TEX]
. If the first number is Unable to parse markup [type=CF_TEX]
, than in every such permutation there are a inversions of form (first element, some other element). So in all permutations beginning with a there are Unable to parse markup [type=CF_TEX]
inversions of this from. Moreover, there are inversions not including the first element, their sum is Unable to parse markup [type=CF_TEX]
. Then, counting sum for all a we have Unable to parse markup [type=CF_TEX]
inversions. - Permutations beginning with
Unable to parse markup [type=CF_TEX]
. At first, we should count the number of inversions, beginning in Unable to parse markup [type=CF_TEX]
. There are Unable to parse markup [type=CF_TEX]
of this form, where cnt is the number of permutations beginning with Unable to parse markup [type=CF_TEX]
and not exceeding p. Then we should count the inversions not beginning in the beginning. But it is the same problem! The only exception is that if Unable to parse markup [type=CF_TEX]
, there are Unable to parse markup [type=CF_TEX]
available numbers less than p1, but not p1. So we get a solution: go from left to right, keep already used numbers in Fenwick tree, and then solve the same problem, assuming that the first number is not pi but Unable to parse markup [type=CF_TEX]
).
The last we should do is to count the number of permutations not exceeding the suffix of p and beginning the same. It can be precomputed, if we go from right to left. In this case we should do the same as in the first part of solution, but consider that the minimal number is a number of already used numbers less than current.
We will describe an algorithm and then understand why it works.
For every prime we will maintain a list of intervals. At the first moment for every pi we add in its list interval
Unable to parse markup [type=CF_TEX]
, other primes have an empty list.
Then we go from big primes to small. Let's consider that current prime is p. If in its list there exists an interval
Unable to parse markup [type=CF_TEX]
, $x < k, y > k$, we divide it into two parts
Unable to parse markup [type=CF_TEX]
and
Unable to parse markup [type=CF_TEX]
.
Then for every interval
Unable to parse markup [type=CF_TEX]
,
Unable to parse markup [type=CF_TEX]
(in fact, in this case
Unable to parse markup [type=CF_TEX]
) we add to the answer for
p Unable to parse markup [type=CF_TEX]
. For intervals, where
Unable to parse markup [type=CF_TEX]
, we add to list of every prime divisor of
Unable to parse markup [type=CF_TEX]
invterval
Unable to parse markup [type=CF_TEX]
. If
Unable to parse markup [type=CF_TEX]
has some prime if more than first power, we should add this segment several times.
After that we should conduct a "union with displacement" operation for every prime which list was changed. If in one list there are 2 invervals
Unable to parse markup [type=CF_TEX]
so that
Unable to parse markup [type=CF_TEX]
, we replace them with one interval
Unable to parse markup [type=CF_TEX]
(so we added
Unable to parse markup [type=CF_TEX]
to the right border of the first interval). Then we go to next (lesser)
p.
Why does it works? If we take function φ one time, for every prime p which divides n, n is divided by p and multiplied by
Unable to parse markup [type=CF_TEX]
(or, the same, by all prime divisors
Unable to parse markup [type=CF_TEX]
in corresponding powers).
Now we can observe that intervals in lists contains the numbers of iterations, when the number contains the corresponding prime number. Bigger primes do not affect smaller, so we can process them earlier. If after i-th iteration the number contains prime number p, after
Unable to parse markup [type=CF_TEX]
-th iteration it contains prime divisors of
Unable to parse markup [type=CF_TEX]
, and we add segments in accordance with this. The k-th iteration is the last, so the existence of the interval
Unable to parse markup [type=CF_TEX]
means that after
k-th iteration we have
Unable to parse markup [type=CF_TEX]
-th power of this prime. From this it is clear why we unite the intervals if that way.
Why does it work fast?
Because we precalculated the minimal prime divisor of each number up to
Unable to parse markup [type=CF_TEX]
using linear Eratosthenes sieve. (Well, it's not necessary)Because for each prime there's no more than
Unable to parse markup [type=CF_TEX]
intervals, because for each Unable to parse markup [type=CF_TEX]
range Unable to parse markup [type=CF_TEX]
. Practically there is no more than 6 segments at once.
Any questions about the editorial are welcome! Especially the English one :)
This post was restored from google cache, and I have edited formula once again. If you notice some mistake, please send be a private message.









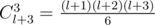 — the total number of ways to increase the sticks not more than
— the total number of ways to increase the sticks not more than 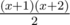 different ways (again we divide
different ways (again we divide 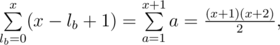
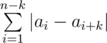 , we can consider each group separately and sum the distances between neighbouring numbers in each group.
, we can consider each group separately and sum the distances between neighbouring numbers in each group. 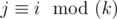 . Let's write down its numbers from left to right:
. Let's write down its numbers from left to right: 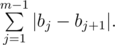
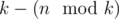 groups of size
groups of size 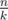 (so called small groups) and
(so called small groups) and 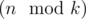 groups of size
groups of size 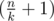 (so called large groups). Consider the following dynamic programming:
(so called large groups). Consider the following dynamic programming: 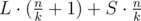 elements of the sorted array
elements of the sorted array 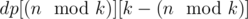 .
.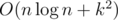 . We can note that in pretests
. We can note that in pretests 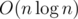 ),
), 

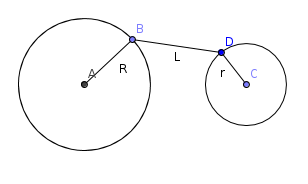
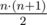 , which doesn't fit in
, which doesn't fit in 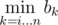 . All that minimums can be found in a single pass through
. All that minimums can be found in a single pass through 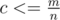 . We call the set of the vertices who are connected with
. We call the set of the vertices who are connected with 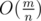 vertices and
vertices and